Climate Policy Vector Database
Vector Embeddings for climate policy legislation

Vector embeddings are essentially converting text or other forms of unstructured data such as audio and images into a high dimension matrix. This high dimensional space is known as an embedding, and can be used to increase the speed and accuracy of search results, as compared to semantic search. In a vector database, queries that have similarities are put together based on similarity, just like K nearest neighbours which makes them much faster to find compared to relational databases. With the ongoing development of technologies such as ChatGPT and other Large Language Models, there is an increasing need for an upgrade from the data base side to match the speed of the models. The enormous number of attributes and features that the model has to draw insights for is endless and take time and computing power to query searches. To solve this issue, using a specialized database that can provide a vector embedding and essentially group the data by semantic meaning, like a K nearest neighbour vector match to draw insights quickly and more accurately than a semantic database.
This project utilized the Climate policy radar database, which consisted of over 4000+ policies and papers that were written regarding climate.
As a researcher for example, almost always when you have a thesis or journal paper or novel idea, then you have to find background articles, papers that other people wrote that are similar but not exactly the same. This can be difficult to find as your idea is novel and assuming you are the first one to write a paper about it, it would not show up on a typical search engine, This is where vector embedded search comes in, if you were to search your paper details, you would be able to find the 10+ journal papers that have the relative closeness of your paper, and reference them much faster.
Objectives
- Build a database based on the Climate Radar Policy
- Create vector embeddings for the climate radar policy features
- Write a python flask search application to query and display results back to users
It was written in Python, using Docker with Weaviate and other supporting libraries.
A docker container was created for all its dependencies. The dataset used was collected from the [Climate Policy Radar]
The dataset made up of approximately 4000+ journals, laws and papers totaled over a 4 year time period. Notable features include, name, summary, category, sector, language, country of origin and outcome of the policy.
class_obj = {
"class": "Article",
"description": "Information regarding Climate Policy",
"properties": [
{
"name": "Document_title",
"dataType": ["string"],
"description": "Document Title",
},
{
"name": "Family_summary",
"dataType": ["string"],
"description": "Document Summary",
},
{
"name": "Category",
"dataType": ["string"],
"description": "Document Category",
},
{
"name": "Sectors",
"dataType": ["string"],
"description": "Document Sector Topics",
},
{
"name": "Keywords",
"dataType": ["string"],
"description": "Document Multiple Keywords",
},
{
"name": "Responses",
"dataType": ["string"],
"description": "Document Publish Response",
},
{
"name": "Language",
"dataType": ["string"],
"description": "Written Language",
},
{
"name": "Geography",
"dataType": ["string"],
"description": "Country of Origin",
}
]
}
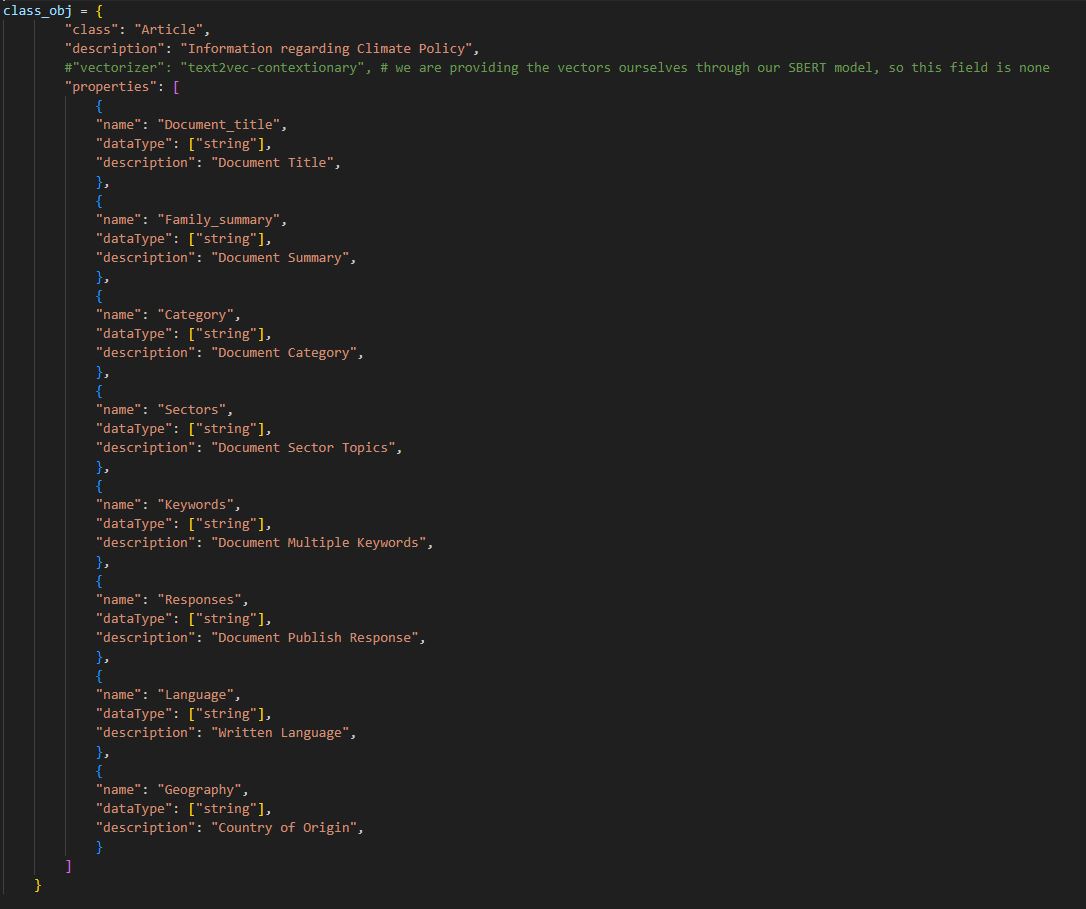
The data was then run through exploratory data analysis: simple data cleaning and text organizing then uploaded to the schema as well.
Flask application
The flask application is connected to the Weaviate Client.
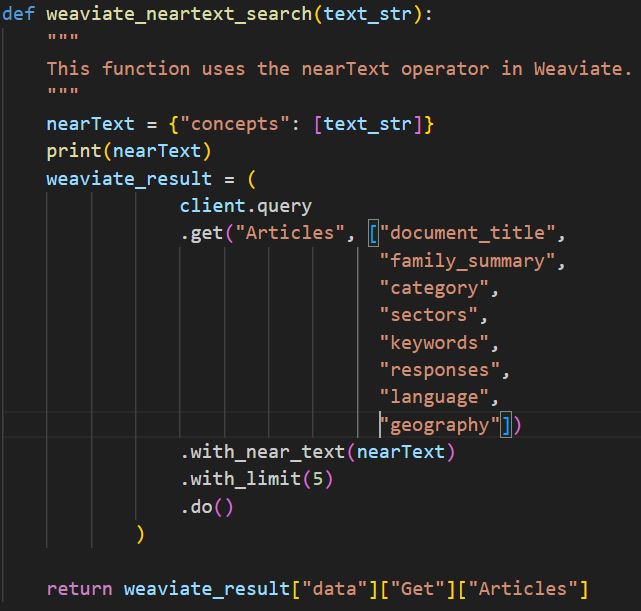
Here the Weaviate nearText operator is used, to search for text that has the closest semantic meanings to the query that the user searched for. The response from the search query will include the closest objects in the climate policy class. The output response is then taken as the name, summary and details of the selected journal article.
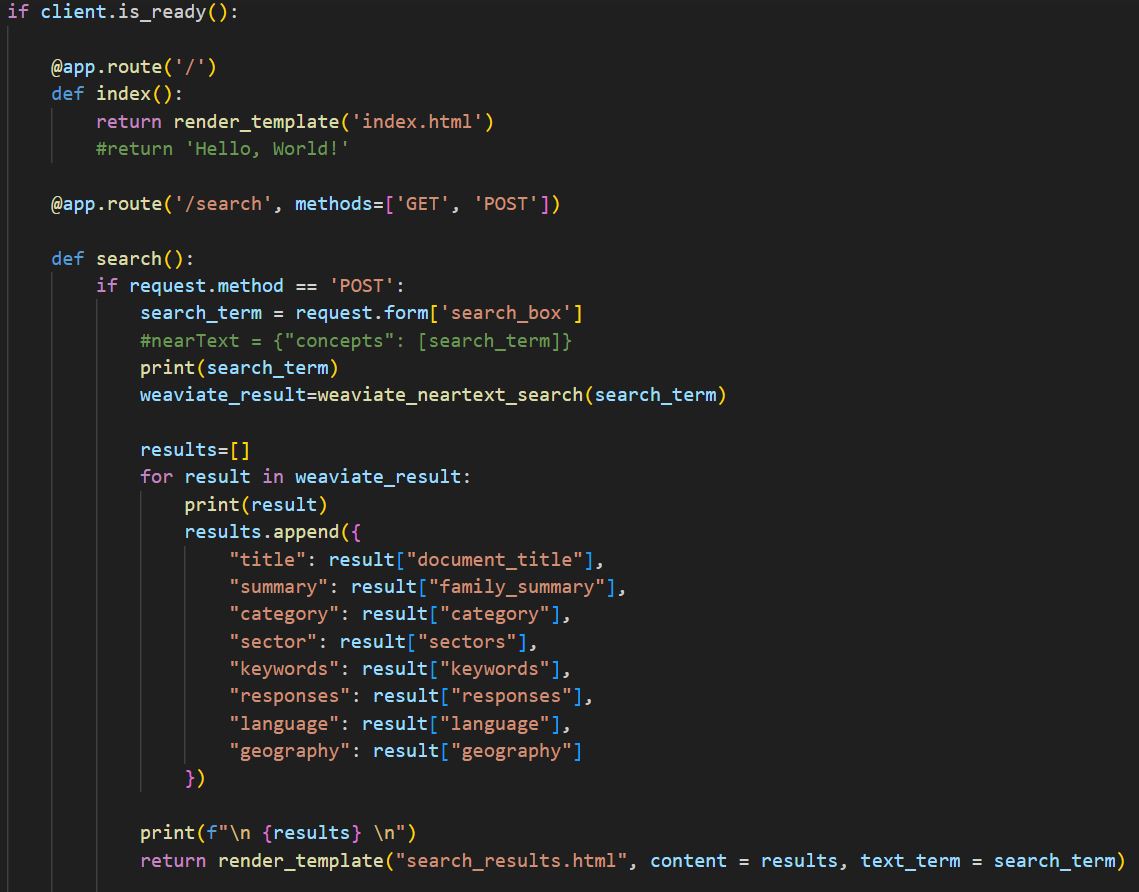
Lastly the flask app front end and back end is created. Firstly the backend for POST requests from Weaviate is created and the search function to return the results from the client and render the page.
The index.html file
The search results.html file
The final website functionality

With relative ease of use, I have created a fully functional vector embedded search engine, for any database files.

This application is not limited to climate policy radar search engine data, the possibilities such as finding shoes that are similar to the ones you own, finding animals that look alike each other. The extensive possibilities for these technologoies with large language models such as chatGPT make it endless.
Libraries:
Some of the tools required to make this project work:
Python - Python is a programming language that lets you work quickly and integrate systems more effectively.
Weaviate - Weaviate is an open-source vector database. It allows you to store data objects and vector embeddings from your favorite ML-models, and scale seamlessly into billions of data objects.
Docker - Docker is a platform designed to help developers build, share, and run modern applications.